Confidential Containers is an open source project that brings confidential computing to Cloud Native environments, leveraging hardware technology to protect complex workloads. Confidential Containers is a CNCF sandbox project.
This is the multi-page printable view of this section. Click here to print.
Documentation
- 1: Overview
- 2: Getting Started
- 2.1: Prerequisites
- 2.1.1: Hardware Requirements
- 2.1.1.1: CoCo without Hardware
- 2.1.1.2: Secure Execution Host Setup
- 2.1.1.3: SEV-SNP Host Setup
- 2.1.1.4: SGX Host Setup
- 2.1.1.5: TDX Host Setup
- 2.1.2: Cloud Hardware
- 2.1.3: Cluster Setup
- 2.2: Installation
- 2.3: Simple Workload
- 3: Architecture
- 3.1: Design Overview
- 3.2: Trust Model
- 3.2.1: Trust Model for Confidential Containers
- 3.2.2: Personas
- 4: Features
- 4.1: Authenticated Registries
- 4.2: Encrypted Images
- 4.3: Local Registries
- 4.4: Protected Storage
- 4.5: Sealed Secrets
- 4.6: Signed Images
- 5: Attestation
- 5.1: Key Broker Service (KBS)
- 5.1.1: KBS backed by AKV
- 5.2: Attestation Service (AS)
- 5.3: Reference Value Provider Service (RVPS)
- 5.4: KBS Client Tool
- 6: Examples
- 6.1: Azure
- 7: Use Cases
- 7.1: Confidential AI
- 7.2: Secure Supply Chain
- 8: Troubleshooting
- 9: Contributing
1 - Overview
High-level overview of Confidential Containers
What is the Confidential Containers project?
Confidential Containers encapsulates pods inside of confidential virtual machines, allowing Cloud Native workloads to leverage confidential computing hardware with minimal modification.
Confidential Containers extends the guarantees of confidential computing to complex workloads. With Confidential Containers, sensitive workloads can be run on untrusted hosts and be protected from compromised or malicious users, software, and administrators.
Confidential Containers provides an end-to-end framework for deploying workloads, attesting them, and provisioning secrets.
What hardware does Confidential Containers support?
On bare metal Confidential Containers supports the following platforms:
| Platform | Supports Attestation | Uses Kata |
|---|---|---|
| Intel TDX | Yes | Yes |
| Intel SGX | Yes | No |
| AMD SEV-SNP | Yes | Yes |
| AMD SEV(-ES) | No | Yes |
| IBM Secure Execution | Yes | Yes |
Confidential Containers can also be deployed in a cloud environment using the
cloud-api-adaptor.
The following platforms are supported.
| Platform | Cloud | Notes |
|---|---|---|
| SNP | Azure | |
| TDX | Azure | |
| Secure Execution | IBM | |
| None | AWS | Under development |
| None | GCP | Under development |
| None | LibVirt | For local testing |
Confidential Containers provides an attestation and key-management engine, called Trustee which is able to attest the following platforms:
| Platform |
|---|
| AMD SEV-SNP |
| Intel TDX |
| Intel SGX |
| AMD SEV-SNP with Azure vTPM |
| Intel TDX with Azure vTPM |
| IBM Secure Execution |
| ARM CCA |
| Hygon CSV |
Trustee can be used with Confidential Containers or to attest standalone confidential guests.
See Attestation section for more information.
2 - Getting Started
High level overview of Confidential Containers
This section will describe hardware and software prerequisites, installing Confidential Containers with an operator, verifying the installation, and running a pod with Confidential Containers.
2.1 - Prerequisites
Requirements for deploying Confidential Containers
This section will describe hardware and software prerequisites, installing Confidential Containers with an operator, verifying the installation, and running a pod with Confidential Containers.
2.1.1 - Hardware Requirements
Hardware requirements for deploying Confidential Containers
Confidential Computing is a hardware technology. Confidential Containers supports multiple hardware platforms and can leverage cloud hardware. If you do not have bare metal hardware and will deploy Confidential Containers with a cloud integration, continue to the cloud section.
You can also run Confidential Containers without hardware support for testing or development.
The Confidential Containers operator, which is described in the following section, does not setup the host kernel, firmware, or system configuration. Before installing Confidential Containers on a bare metal system, make sure that your node can start confidential VMs.
This section will describe the configuration that is required on the host.
Regardless of your platform, it is recommended to have at least 8GB of RAM and 4 cores on your worker node.
2.1.1.1 - CoCo without Hardware
Testing and development without hardware
For testing or development, Confidential Containers can be deployed without any hardware support.
This is referred to as a coco-dev or non-tee.
A coco-dev deployment functions the same way as Confidential Containers
with an enclave, but a non-confidential VM is used instead of a confidential VM.
This does not provide any security guarantees, but it can be used for testing.
No additional host configuration is required as long as the host supports virtualization.
2.1.1.2 - Secure Execution Host Setup
Host configurations for IBM s390x
TODO
2.1.1.3 - SEV-SNP Host Setup
Host configurations for AMD SEV-SNP machines
TODO
2.1.1.4 - SGX Host Setup
Host configurations for Intel SGX machines
TODO
2.1.1.5 - TDX Host Setup
Host configurations for Intel TDX machines
TODO
2.1.2 - Cloud Hardware
Confidential Containers on the Cloud
Note
If you are using bare metal confidential hardware, you can skip this section.Confidential Containers can be deployed via confidential computing cloud offerings. The main method of doing this is to use the cloud-api-adaptor also known as “peer pods.”
Some clouds also support starting confidential VMs inside of non-confidential VMs. With Confidential Containers these offerings can be used as if they were bare-metal.
2.1.3 - Cluster Setup
Cluster prerequisites
Confidential Containers requires Kubernetes. A cluster must be installed before running the operator. Many different clusters can be used but they should meet the following requirements.
- The minimum Kubernetes version is 1.24
- Cluster must use
containerdorcri-o. - At least one node has the label
node-role.kubernetes.io/worker=. - SELinux is not enabled.
If you use Minikube or Kind to setup your cluster, you will only be able to use runtime classes based on Cloud Hypervisor due to an issue with QEMU.
2.2 - Installation
Installing Confidential Containers with the operator
Note
Make sure you have completed the pre-requisites before installing Confidential Containers.Deploy the operator
Deploy the operator by running the following command where <RELEASE_VERSION> needs to be substituted
with the desired release tag.
kubectl apply -k github.com/confidential-containers/operator/config/release?ref=<RELEASE_VERSION>
For example, to deploy the v0.10.0 release run:
kubectl apply -k github.com/confidential-containers/operator/config/release?ref=v0.10.0
Wait until each pod has the STATUS of Running.
kubectl get pods -n confidential-containers-system --watch
Create the custom resource
Creating a custom resource installs the required CC runtime pieces into the cluster node and creates the runtime classes.
kubectl apply -k github.com/confidential-containers/operator/config/samples/ccruntime/default?ref=<RELEASE_VERSION>
kubectl apply -k github.com/confidential-containers/operator/config/samples/ccruntime/s390x?ref=<RELEASE_VERSION>
kubectl apply -k github.com/confidential-containers/operator/config/samples/enclave-cc/hw?ref=<RELEASE_VERSION>
Note
If using enclave-cc with SGX, please refer to this guide for more information on setting the custom resource.Wait until each pod has the STATUS of Running.
kubectl get pods -n confidential-containers-system --watch
Verify Installation
See if the expected runtime classes were created.
kubectl get runtimeclass
Should return
NAME HANDLER AGE
kata kata-qemu 8d
kata-clh kata-clh 8d
kata-qemu kata-qemu 8d
kata-qemu-coco-dev kata-qemu-coco-dev 8d
kata-qemu-sev kata-qemu-sev 8d
kata-qemu-snp kata-qemu-snp 8d
kata-qemu-tdx kata-qemu-tdx 8d
NAME HANDLER AGE
kata kata-qemu 60s
kata-qemu kata-qemu 61s
kata-qemu-se kata-qemu-se 61s
NAME HANDLER AGE
enclave-cc enclave-cc 9m55s
Runtime Classes
CoCo supports many different runtime classes. Different deployment types install different sets of runtime classes. The operator may install some runtime classes that are not valid for your system. For example, if you run the operator on a TDX machine, you might have TDX and SEV runtime classes. Use the runtime classes that match your hardware.
| Name | Type | Description |
|---|---|---|
kata |
x86 | Alias of the default runtime handler (usually the same as kata-qemu) |
kata-clh |
x86 | Kata Containers (non-confidential) using Cloud Hypervisor |
kata-qemu |
x86 | Kata Containers (non-confidential) using QEMU |
kata-qemu-coco-dev |
x86 | CoCo without an enclave (for testing only) |
kata-qemu-sev |
x86 | CoCo with QEMU for AMD SEV HW |
kata-qemu-snp |
x86 | CoCo with QEMU for AMD SNP HW |
kata-qemu-tdx |
x86 | CoCo with QEMU for Intel TDX HW |
kata-qemu-se |
s390x | CoCO with QEMU for Secure Execution |
enclave-cc |
SGX | CoCo with enclave-cc (process-based isolation without Kata) |
2.3 - Simple Workload
Running a simple confidential workload
Creating a sample Confidential Containers workload
Once you’ve used the operator to install Confidential Containers, you can run a pod with CoCo by simply adding a runtime class.
First, we will use the kata-qemu-coco-dev runtime class which uses CoCo without hardware support.
Initially we will try this with an unencrypted container image.
In this example, we will be using the bitnami/nginx image as described in the following yaml:
apiVersion: v1
kind: Pod
metadata:
labels:
run: nginx
name: nginx
annotations:
io.containerd.cri.runtime-handler: kata-qemu-coco-dev
spec:
containers:
- image: bitnami/nginx:1.22.0
name: nginx
dnsPolicy: ClusterFirst
runtimeClassName: kata-qemu-coco-dev
Setting the runtimeClassName is usually the only change needed to the pod yaml, but some platforms
support additional annotations for configuring the enclave. See the guides for
more details.
With Confidential Containers, the workload container images are never downloaded on the host. For verifying that the container image doesn’t exist on the host, you should log into the k8s node and ensure the following command returns an empty result:
root@cluster01-master-0:/home/ubuntu# crictl -r unix:///run/containerd/containerd.sock image ls | grep bitnami/nginx
You will run this command again after the container has started.
Create a pod YAML file as previously described (we named it nginx.yaml) .
Create the workload:
kubectl apply -f nginx.yaml
Output:
pod/nginx created
Ensure the pod was created successfully (in running state):
kubectl get pods
Output:
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 3m50s
3 - Architecture
Architectural Details of the Confidential Containers Project
3.1 - Design Overview
The basic ideas behind Confidential Containers
Confidential computing projects are largely defined by what is inside the enclave and what is not. For Confidential Containers, the enclave contains the workload pod and helper processes and daemons that facilitate the workload pod. Everything else, including the hypervisor, other pods, and the control plane, is outside of the enclave and untrusted. This division is carefully considered to balance TCB size and sharing.
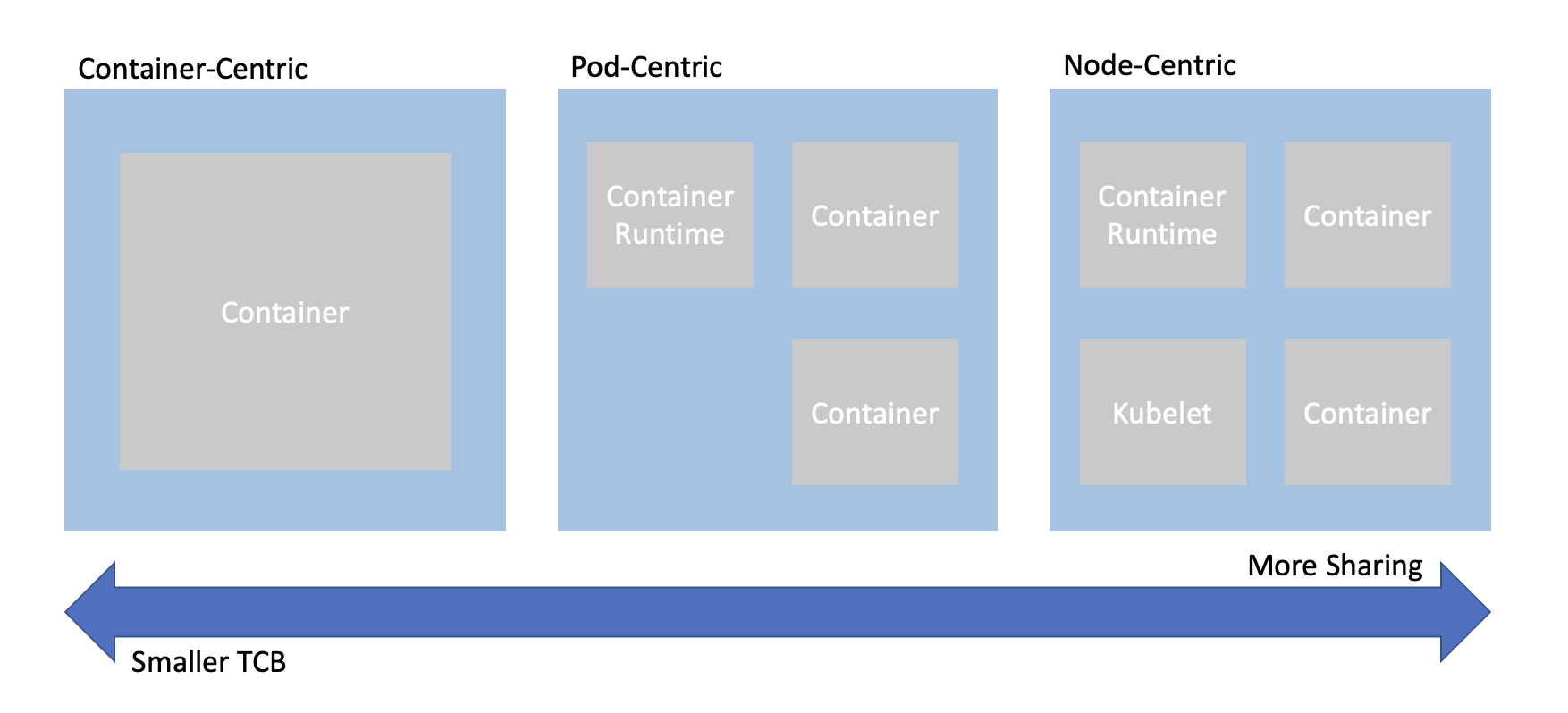
When trying to combine confidential computing and cloud native computing, often the first thing that comes to mind is either to put just one container inside of an enclave, or to put an entire worker node inside of the an enclave. This is known as container-centeric virtualization or node-centric virtualization. Confidential Containers opts for a compromise between these approaches which avoids some of their pitfalls. Specifically, node-centric approaches tend to have a large TCB that includes components such as the Kubelet. This makes the attack surface of the confidential guest significantly larger. It is also difficult to implement managed clusters in node-centric approaches because the workload runs in the same context as the rest of the cluster. On the other hand, container-centric approaches can support very little sharing of resources. Sharing is a loose term, but one example is two containers that need to share information over the network. In a container-centric approach this traffic would leave the enclave. Protecting the traffic would add overhead and complexity.
Confidential Containers takes a pod-centric approach which balances TCB size and sharing. While Confidential Containers does have some daemons and processes inside the enclave, the API of the guest is relatively small. Furthermore the guest image is static and generic across workloads and even platforms, making it simpler to ensure security guarantees. At the same time, sharing between containers in the same pod is easy. For example, the pod network namespace doesn’t leave the enclave, so containers can communicate confidentially on it without additional overhead. These are just a few of the reasons why pod-centric virtualization seems to be the best way to provide confidential cloud native computing.
Kata Containers
Confidential Containers and Kata Containers are closely linked, but the relationship might not be obvious at first. Kata Containers is an existing open source project that encapsulates pods inside of VMs. Given the pod-centric design of Confidential Containers this is a perfect match. But if Kata runs pods inside of VM, why do we need the Confidential Containers project at all? There are crucial changes needed on top of Kata Containers to preserve confidentiality.
Image Pulling
When using Kata Containers container images are pulled on the worker node with the help of a CRI runtime like containerd.
The images are exposed to the guest via filesystem passthrough.
This is not suitable for confidential workloads because the container images are exposed to the untrusted host.
With Confidential Containers images are pulled and unpacked inside of the guest.
This requires additional components such as image-rs to be part of the guest rootfs.
These components are beyond the scope of traditional Kata deployments and live in the Confidential Containers
guest components repository.
On the host, we use a snapshotter to pre-empt image pull and divert control flow to image-rs inside the guest.
sequenceDiagram
kubelet->>containerd: create container
containerd->>nydus snapshotter: load container snapshot
nydus snapshotter->>image-rs: download container
kubelet->>containerd: start container
containerd->>kata shim: start container
kata shim->>kata agent: start container
The above is a simplified diagram showing the interaction of containerd, the nydus snapshotter, and image-rs. The diagram does not show the creation of the sandbox.
Attestation
Confidential Containers also provides components inside the guest and elsewhere to facilitate attestation.
Attestation is a crucial part of confidential computing and a direct requirement of many guest operations.
For example, to unpack an encrypted container image, the guest must retrieve a secret key.
Inside the guest the confidential-data-hub and attestation-agent handle operations involving
secrets and attestation.
Again, these components are beyond the scope of traditional Kata deployments and are located in the
guest components repository.
The CDH and AA use the KBS Protocol to communicate with an external, trusted entity. Confidential Containers provides Trustee as an attestation service and key management engine that validates the guest TCB and releases secret resources.
sequenceDiagram
workload->>CDH: request secret
CDH->>AA: get attestation token
AA->>KBS: attestation request
KBS->>AA: challenge
AA->>KBS: attestation
KBS->>AA: attestation token
AA->>CDH: attestation token
CDH->>KBS: secret request
KBS->>CDH: encrypted secret
CDH->>workload: secret
The above is a somewhat simplified diagram of the attestation process. The diagram does not show the details of how the workload interacts with the CDH.
Putting the pieces together
If we take Kata Containers and add guest image pulling and attestation, we arrive at the following diagram, which represents Confidential Containers.
flowchart TD
kubelet-->containerd
containerd-->kata-shim
kata-shim-->hypervisor
containerd-->nydus-snapshotter
subgraph guest
kata-agent-->pod
ASR-->CDH
CDH<-->AA
pod-->ASR
image-rs-->pod
image-rs-->CDH
end
subgraph pod
container-a
container-b
container-c
end
subgraph Trustee
KBS-->AS
AS-->RVPS
end
AA-->KBS
CDH-->KBS
nydus-snapshotter-->image-rs
hypervisor-->guest
kata-shim<-->kata-agent
image-rs<-->registry
Clouds and Nesting
Most confidential computing hardware does not support nesting. More specifically, a confidential guest cannot be started inside of a confidential guest, and with few exceptions a confidential guest cannot be started inside of a non-confidential guest. This poses a challenge for those who do not have access to bare metal machines or would like to have virtual worker nodes.
To alleviate this, Confidential Containers supports a deployment mode known as Peer Pods, where a component called the Cloud API Adaptor takes the place of a conventional hypervisor. Rather than starting a confidential podvm locally, the CAA reaches out to a cloud API. Since the podvm is no longer started locally the worker node can be virtualized. This also allows confidential containers to integrate with cloud confidential VM offerings.
Peer Pods deployments share most of the same properties that are described in this guide.
Process-based Isolation
Confidential Containers also supports SGX with enclave-cc. Because the Kata guest cannot be run as a single process, the design of enclave-cc is significantly different. In fact, enclave-cc doesn’t use Kata at all, but it does still represent a pod-centric approach with some sharing between containers even as they run in separate enclaves. enclave-cc does use some of the guest components as crates.
Components
Confidential Containers integrates many components. Here is a brief overview of most the components related to the project.
| Component | Repository | Purpose |
|---|---|---|
| Operator | operator | Installs Confidential Containers |
| Kata Shim | kata-containers/kata-containers | Starts PodVM and proxies requests to Kata Agent |
| Kata Agent | kata-containers/kata-containers | Sets up and runs the workload inside of a VM |
| image-rs | guest-componenents | Downloads and unpacks container images |
| ocicrypt-rs | guest-components | Decrypts encrypted container layers |
| confidential-data-hub | guest-components | Handles secret resources |
| attestation-agent | guest-components | Attests guest |
| api-server-rest | guest-components | Proxies requests from workload container to CDH |
| key-broker-service | Trustee | Coordinates attestation and secret delivery (relying party) |
| attestation-service | Trustee | Validate hardware evidence (verifier) |
| reference-value-provider-service | Trustee | Manages reference values |
| Nydus Snapshotter | containerd/nydus-snapshotter | Triggers guest image pulling |
| cloud-api-adaptor | cloud-api-adaptor | Starts PodVM in the cloud |
| agent-protocol-forwarder | cloud-api-adaptor | Forwards Kata Agent API from cloud API |
Component Dependencies
Many of the above components depend on each other either directly in the source, during packaging, or at runtime. The basic premise is that the operator deploys a special configuration of Kata containers that uses a rootfs (build by the Kata CI) that includes the guest components. This diagram shows these relationships in more detail. The diagram does not capture runtime interactions.
flowchart LR
Trustee --> Versions.yaml
Guest-Components --> Versions.yaml
Kata --> kustomization.yaml
Guest-Components .-> Client-tool
Guest-Components --> enclave-agent
enclave-cc --> kustomization.yaml
Guest-Components --> versions.yaml
Trustee --> versions.yaml
Kata --> versions.yaml
subgraph Kata
Versions.yaml
end
subgraph Guest-Components
end
subgraph Trustee
Client-tool
end
subgraph enclave-cc
enclave-agent
end
subgraph Operator
kustomization.yaml
reqs-deploy
end
subgraph cloud-api-adaptor
versions.yaml
end
Workloads
Confidential Containers provides a set of primitives for building confidential Cloud Native applications. For instance, it allows a pod to be run inside of a confidential VM, it handles encrypted and signed container image, sealed secrets, and other features described in the features section. This does not guarantee that any application run with Confidential Containers is confidential or secure. Users deploying applications with Confidential Containers should understand the attack surface and security applications of their workloads, focusing especially on APIs that cross the confidential trust boundary.
3.2 - Trust Model
Documentation on the Confidential Containers trust model
3.2.1 - Trust Model for Confidential Containers
Overview of Confidential Containers security
Confidential Containers mainly relies on VM enclaves, where the guest does not trust the host. Confidential computing, and by extension Confidential Containers, provides technical assurances that the untrusted host cannot access guest data or manipulate guest control flow.
Trusted
Confidential Containers maps pods to confidential VMs, meaning that everything inside a pod is
within an enclave. In addition to the workload pod, the guest also contains helper processes
and daemons to setup and control the pod.
These include the kata-agent, and guest components as described in the architecture section.
More specifically, the guest is defined as four components.
- Guest firmware
- Guest kernel
- Guest kernel command line
- Guest root filesystem
All platforms supported by Confidential Containers must measure these four components. Details about the mechanisms for each platform are below.
Note that the hardware measurement usually does not directly cover the workload containers. Instead, containers are covered by a second-stage of measurement that uses generic OCI standards such as signing. This second stage of measurement is rooted in the trust of the first stage, but decoupled from the guest image.
Confidential Containers also relies on an external trusted entity, usually Trustee, to attest the guest.
Untrusted
Everything on the host outside of the enclave is untrusted. This includes the Kubelet, CRI runtimes like containerd, the host kernel, the Kata Shim, and more.
Since the Kubernetes control plane is untrusted, some traditional Kubernetes security techniques are not relevant to Confidential Containers without special considerations.
Crossing the trust boundary
In confidential computing careful scrutiny is required whenever information crosses the boundary between the trusted and untrusted contexts. Secrets should not leave the enclave without protection and entities outside of the enclave should not be able to trigger malicious behavior inside the guest.
In Confidential Containers there are APIs that cross the trust boundary. The main example is the API between the Kata Agent in the guest and the Kata Shim on the host. This API is protected with an OPA policy running inside the guest that can block malicious requests by the host.
Note that the kernel command line, which is used to configure the Kata Agent, does not cross the trust boundary because it is measured at boot. Assuming that the guest measurement is validated, the APIs that are most significant are those that are not measured by the hardware.
Quantifying the attack surface of an API is non-trivial. The Kata Agent can perform complex operations such as mounting a block device provided by the host. In the case that a host-provided device is attached to the guest the attack surface is extended to any information provided by this device. It’s also possible that any of the code used to implement the API inside the guest has a bug in it. As the complexity of the API increases, the likelihood of a bug increases. The nuances of the Kata Agent API is why Confidential Containers relies on a dynamic and user-configurable policy to either block endpoints entirely or only allow particular types of requests to be made. For example, the policy can be used to make sure that a block device is mounted only to a particular location.
Applications deployed with Confidential Containers should also be aware of the trust boundary. An application running inside of an enclave is not secure if it exposes a dangerous API to the outside world. Confidential applications should almost always be deployed with signed and/or encrypted images. Otherwise the container image itself can be considered as part of the unmeasured API.
Out of Scope
Some attack vectors are out of scope of confidential computing and Confidential Containers. For instance, confidential computing platforms usually do not protect against hardware side-channels. Neither does Confidential Containers. Different hardware platforms and platform generations may have different guarantees regarding properties like memory integrity. Confidential Containers inherits the properties of whatever TEE it is using.
Confidential computing does not protect against denial of service. Since the untrusted host is in charge of scheduling, it can simply not run the guest. This is true for Confidential Containers as well. In Confidential Containers the untrusted host can avoid scheduling the pod VM and the untrusted control plane can avoid scheduling the pod. These are seen as equivalent.
In general orchestration is untrusted in Confidential Containers. Confidential Containers provides few guarantees about where, when, or in what order workloads run, besides that the workload is deployed inside of a genuine enclave containing the expected software stack.
Cloud Native Personas
So far the trust model has been described in terms of a host and a guest, following from the underlying confidential computing trust model, but these terms are not used in cloud native computing. How do we understand the trust model in terms of cloud native personas? Confidential Containers is a flexible project. It does not explicitly define how parties should interact. but some possible arrangements are described in the personas section.
Measurement Details
As mentioned above, all hardware platforms must measure the four components representing the guest image. This table describes how each platform does this.
| Platform | Firmware | Kernel | Command Line | Rootfs |
|---|---|---|---|---|
| SEV-SNP | Pre-measured by ASP | Measured direct boot via OVMF | Measured direct boot | Measured direct boot |
| TDX | Pre-launch measurement | RTMR | RTMR | Dm-verity hash provided in command line |
| SE | Included in encrypted SE image | included in SE image | included in SE image | included in SE image |
See Also
- Confidential Computing Consortium (CCC) published “A Technical Analysis of Confidential Computing” section 5 of which defines the threat model for confidential computing.
- CNCF Security Technical Advisory Group published “Cloud Native Security Whitepaper”
- Kubernetes provides documentation : “Overview of Cloud Native Security”
- Open Web Application Security Project - “Docker Security Threat Modeling”
3.2.2 - Personas
Description and discussion of relevant agents/actors in the context of Confidential Containers
Personas
Otherwise referred to as actors or agents, these are individuals or groups capable of carrying out a particular threat. In identifying personas we consider :
- The Runtime Environment, Figure 5, Page 19 of CNCF Cloud Native Security Paper. This highlights three layers, Cloud/Environment, Workload Orchestration, Application.
- The Kubernetes Overview of Cloud Native Security identifies the 4C’s of Cloud Native Security as Cloud, Cluster, Container and Code. However data is core to confidential containers rather than code.
- The Confidential Computing Consortium paper A Technical Analysis of Confidential Computing defines Confidential Computing as the protection of data in use by performing computations in a hardware-based Trusted Execution Environment (TEE).
In considering personas we recognise that a trust boundary exists between each persona and we explore how the least privilege principle (as described on Page 40 of Cloud Native Security Paper ) should apply to any actions which cross these boundaries.
Confidential containers can provide enhancements to ensure that the expected code/containers are the only code that can operate over the data. However any vulnerabilities within this code are not mitigated by using confidential containers, the Cloud Native Security Whitepaper details Lifecycle aspects that relate to the security of the code being placed into containers such as Static/Dynamic Analysis, Security Tests, Code Review etc which must still be followed.

Any of these personas could attempt to perform malicious actions:
Infrastructure Operator
This persona has privileges within the Cloud Infrastructure which includes the hardware and firmware used to provide compute, network and storage to the Cloud Native solution. They are responsible for availability of infrastructure used by the cloud native environment.
- Have access to the physical hardware.
- Have access to the processes involved in the deployment of compute/storage/memory used by any orchestration components and by the workload.
- Have control over TEE hardware availability/type.
- Responsibility for applying firmware updates to infrastructure including the TEE Technology.
Examples: Cloud Service Provider (CSP), Site Reliability Engineer, etc. (SRE)
Orchestration Operator
This persona has privileges within the Orchestration/Cluster. They are responsible for deploying a solution into a particular cloud native environment and managing the orchestration environment. For managed cluster this would also include the administration of the cluster control plane.
- Control availability of service.
- Control webhooks and deployment of workloads.
- Control availability of cluster resources (data/networking/storage) and cluster services (Logging/Monitoring/Load Balancing) for the workloads.
- Control the deployment of runtime artifacts required by the TEE during initialisation, before hosting the confidential workload.
Example: A Kubernetes administrator responsible for deploying pods to a cluster and maintaining the cluster.
Workload Provider
This persona designs and creates the orchestration objects comprising the solution (e.g. Kubernetes Pod spec, etc). These objects reference containers published by Container Image Providers. In some cases the Workload and Container Image Providers may be the same entity. The solution defined is intended to provide the Application or Workload which in turn provides value to the Data Owners (customers and clients). The Workload Provider and Data Owner could be part of same company/organisation but following the least privilege principle the Workload Provider should not be able to view or manipulate end user data without informed consent.
- Need to prove to customer aspects of compliance.
- Defines what the solution requires in order to run and maintain compliance (resources, utility containers/services, storage).
- Chooses the method of verifying the container images (from those supported by Container Image Provider) and obtains artifacts needed to allow verification to be completed within the TEE.
- Provide the boot images initially required by the TEE during initialisation or designates a trusted party to do so.
- Provide the attestation verification service, or designate a trusted party to provide the attestation verification service.
Examples: 3rd party software vendor, CSP
Container Image Provider
This persona is responsible for the part of the supply chain that builds container images and provides them for use by the solution. Since a workload can be composed of multiple containers, there may be multiple container image providers, some will be closely connected to the workload provider (business logic containers), others more independent to the workload provider (side car containers). The container image provider is expected to use a mechanism to allow provenance of container image to be established when a workload pulls in these images at deployment time. This can take the form of signing or encrypting the container images.
- Builds container images.
- Owner of business logic containers. These may contain proprietary algorithms, models or secrets.
- Signs or encrypts the images.
- Defines the methods available for verifying the container images to be used.
- Publishes the signature verification key (public key).
- Provides any decryption keys through a secure channel (generally to a key management system controlled by a Key Broker Service).
- Provides other required verification artifacts (secure channel may be considered).
- Protects the keys used to sign or encrypt the container images.
It is recognised that hybrid options exist surrounding workload provider and container provider. For example the workload provider may choose to protect their supply chain by signing/encrypting their own container images after following the build patterns already established by the container image provider.
Example : Istio
Data Owner
Owner of data used, and manipulated by the application.
- Concerned with visibility and integrity of their data.
- Concerned with compliance and protection of their data.
- Uses and shares data with solutions.
- Wishes to ensure no visibility or manipulation of data is possible by Orchestration Operator or Cloud Operator personas.
Discussion
Data Owner vs. All Other Personas
The key trust relationship here is between the Data Owner and the other personas. The Data Owner trusts the code in the form of container images chosen by the Workload Provider to operate across their data, however they do not trust the Orchestration Operator or Cloud Operator with their data and wish to ensure data confidentiality.
Workload Provider vs. Container Image Provider
The Workload Provider is free to choose Container Image Providers that will provide not only the images they need but also support the verification method they require. A key aspect to this relationship is the Workload Provider applying Supply Chain Security practices (as described on Page 42 of Cloud Native Security Paper ) when considering Container Image Providers. So the Container Image Provider must support the Workload Providers ability to provide assurance to the Data Owner regarding integrity of the code.
With Confidential Containers we match the TEE boundary to the most restrictive boundary which is between the Workload Provider and the Orchestration Operator.
Orchestration Operator vs. Infrastructure Operator
Outside the TEE we distinguish between the Orchestration Operator and the Infrastructure Operator due to nature of how they can impact the TEE and the concerns of Workload Provider and Data Owner. Direct threats exist from the Orchestration Operator as some orchestration actions must be permitted to cross the TEE boundary otherwise orchestration cannot occur. A key goal is to deprivilege orchestration and restrict the Orchestration Operators privileges across the boundary. However indirect threats exist from the Infrastructure Operator who would not be permitted to exercise orchestration APIs but could exploit the low-level hardware or firmware capabilities to access or impact the contents of a TEE.
Workload Provider vs. Data Owner
Inside the TEE we need to be able to distinguish between the Workload Provider and Data Owner in recognition that the same workload (or parts such as logging/monitoring etc) can be re-used with different data sets to provide a service/solution. In the case of bespoke workload, the workload provider and Data Owner may be the same persona. As mentioned the Data Owner must have a level of trust in the Workload Provider to use and expose the data provided in an expected and approved manner. Page 10 of A Technical Analysis of Confidential Computing , suggests some approaches to establish trust between them.
The TEE boundary allows the introduction of secrets but just as we recognised the TEE does not provide protection from code vulnerabilities, we also recognised that a TEE cannot enforce complete distrust between Workload Provider and Data Owner. This means secrets within the TEE are at risk from both Workload Provider and Data Owner and trying to keep secrets which protect the workload (container encryption etc), separated from secrets to protect the data (data encryption) is not provided simply by using a TEE.
Recognising that Data Owner and Workload Provider are separate personas helps us to identify threats to both data and workload independently and to recognise that any solution must consider the potential independent nature of these personas. Two examples of trust between Data Owner and Workload Provider are :
- AI Models which are proprietary and protected requires the workload to be encrypted and not shared with the Data Owner. In this case secrets private to the Workload Provider are needed to access the workload, secrets requiring access to the data are provided by the Data Owner while trusting the workload/model without having direct access to how the workload functions. The Data Owner completely trusts the workload and Workload Provider, whereas the Workload Provider does not trust the Data Owner with the full details of their workload.
- Data Owner verifies and approves certain versions of a workload, the workload provides the data owner with secrets in order to fulfil this. These secrets are available in the TEE for use by the Data Owner to verify the workload, once achieved the data owner will then provide secrets and data into the TEE for use by the workload in full confidence of what the workload will do with their data. The Data Owner will independently verify versions of the workload and will only trust specific versions of the workload with the data whereas the Workload Provider completely trusts the Data Owner.
Data Owner vs. End User
We do not draw a distinction between data owner and end user though we do recognise that in some cases these may not be identical. For example data may be provided to a workload to allow analysis and results to be made available to an end user. The original data is never provided directly to the end user but the derived data is, in this case the data owner can be different from the end user and may wish to protect this data from the end user.
4 - Features
Primitives provided by Confidential Containers
In addition to running pods inside of enclaves, Confidential Containers provides several other features that can be used to protect workloads and data. Securing complex workloads often requires using some of these features.
Most features depend on and require attestation, which is described in the next section.
4.1 - Authenticated Registries
Use private registries with Confidential Containers
TODO
4.2 - Encrypted Images
Procedures to encrypt and consume OCI images in a TEE
Context
A user might want to bundle sensitive data on an OCI (Docker) image. The image layers should only be accessible within a Trusted Execution Environment (TEE).
The project provides the means to encrypt an image with a symmetric key that is released to the TEE only after successful verification and appraisal in a Remote Attestation process. CoCo infrastructure components within the TEE will transparently decrypt the image layers as they are pulled from a registry without exposing the decrypted data outside the boundaries of the TEE.
Instructions
The following steps require a functional CoCo installation on a Kubernetes cluster. A Key Broker Client (KBC) has to be configured for TEEs to be able to retrieve confidential secrets. We assume cc_kbc as a KBC for the CoCo project’s Key Broker Service (KBS) in the following instructions, but image encryption should work with other Key Broker implementations in a similar fashion.
Please ensure you have a recent version of Skopeo (v1.14.2+) installed locally.
Encrypt an image
We extend public image with secret data.
docker build -t unencrypted - <<EOF
FROM nginx:stable
RUN echo "something confidential" > /secret
EOF
The encryption key needs to be a 32 byte sequence and provided to the encryption step as base64-encoded string.
KEY_FILE="image_key"
head -c 32 /dev/urandom | openssl enc > "$KEY_FILE"
KEY_B64="$(base64 < $KEY_FILE)"
The key id is a generic resource descriptor used by the key broker to look up secrets in its storage. For KBS this is composed of three segments: $repository_name/$resource_type/$resource_tag
KEY_PATH="/default/image_key/nginx"
KEY_ID="kbs://${KEY_PATH}"
The image encryption logic is bundled and invoked in a container:
git clone https://github.com/confidential-containers/guest-components.git
cd guest-components
docker build -t coco-keyprovider -f ./attestation-agent/docker/Dockerfile.keyprovider .
To access the image from within the container, Skopeo can be used to buffer the image in a directory, which is then made available to the container. Similarly, the resulting encrypted image will be put into an output directory.
mkdir -p oci/{input,output}
skopeo copy docker-daemon:unencrypted:latest dir:./oci/input
docker run -v "${PWD}/oci:/oci" coco-keyprovider /encrypt.sh -k "$KEY_B64" -i "$KEY_ID" -s dir:/oci/input -d dir:/oci/output
We can inspect layer annotations to confirm the expected encryption was applied:
skopeo inspect dir:./oci/output | jq '.LayersData[0].Annotations["org.opencontainers.image.enc.keys.provider.attestation-agent"] | @base64d | fromjson'
{
"kid": "kbs:///default/image_key/nginx",
"wrapped_data": "lGaLf2Ge5bwYXHO2g2riJRXyr5a2zrhiXLQnOzZ1LKEQ4ePyE8bWi1GswfBNFkZdd2Abvbvn17XzpOoQETmYPqde0oaYAqVTMcnzTlgdYYzpWZcb3X0ymf9bS0gmMkqO3dPH+Jf4axXuic+ITOKy7MfSVGTLzay6jH/PnSc5TJ2WuUJY2rRtNaTY65kKF2K9YP6mtYBqcHqvPDlFiVNNeTAGv2w1zwaMlgZaSHV+Z1y+xxbOV5e98bxuo6861rMchjCiE7FY37PHD3a5ISogq90=",
"iv": "Z8bGQL7r6qxSpd4L",
"wrap_type": "A256GCM"
}
Finally the resulting encrypted image can be provisioned to an image registry.
ENCRYPTED_IMAGE=some-private.registry.io/coco/nginx:encrypted
skopeo copy dir:./oci/output "docker://${ENCRYPTED_IMAGE}"
Provision image key
Prior to launching a Pod the image key needs to be provisioned to the Key Broker’s repository. For a KBS deployment on Kubernetes using the local filesystem as repository storage it would work like this:
kubectl exec deploy/kbs -- mkdir -p "/opt/confidential-containers/kbs/repository/$(dirname "$KEY_PATH")"
cat "$KEY_FILE" | kubectl exec -i deploy/kbs -- tee "/opt/confidential-containers/kbs/repository/${KEY_PATH}" > /dev/null
Launch a Pod
In this example we default to the Cloud API Adaptor runtime, adjust this depending on the CoCo installation.
kubectl get runtimeclass -o jsonpath='{.items[].handler}'
kata-remote
CC_RUNTIMECLASS=kata-remote
We create a simple deployment using our encrypted image. As the image is being pulled and the CoCo components in the TEE encounter the layer annotations that we saw above, the image key will be retrieved from the Key Broker using the annotated Key ID and the layers will be decrypted transparently and the container should come up.
cat <<EOF> nginx-encrypted.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx-encrypted
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
annotations:
io.containerd.cri.runtime-handler: ${CC_RUNTIMECLASS}
spec:
runtimeClassName: ${CC_RUNTIMECLASS}
containers:
- image: ${ENCRYPTED_IMAGE}
name: nginx
EOF
kubectl apply -f nginx-encrypted.yaml
We can confirm that the image key has been retrieved from KBS.
kubectl logs -f deploy/kbs | grep "$KEY_PATH"
[2024-01-23T10:24:52Z INFO actix_web::middleware::logger] 10.244.0.1 "GET /kbs/v0/resource/default/image_key/nginx HTTP/1.1" 200 530 "-" "attestation-agent-kbs-client/0.1.0" 0.000670
4.3 - Local Registries
Pull containers from self-hosted registries
TODO
4.4 - Protected Storage
Add protected volumes to a pod
TODO
4.5 - Sealed Secrets
Generate and deploy protected Kubernetes secrets
Note
Sealed Secrets depend on attestation. Configure attestation before using sealed secrets.Sealed secrets allow confidential information to be stored in the untrusted control plane. Like normal Kubernetes secrets, sealed secrets are orchestrated by the control plane and are transparently provisioned to your workload as environment variables or volumes.
Basic Usage
Here’s how you create a vault secret. There are also envelope secrets, which are described later. Vault secrets are a pointer to resource stored in a KBS, while envelope secrets are wrapped secrets that are unwrapped with a KMS.
Creating a sealed secret
There is a helper tool for sealed secrets in the Guest Components repository.
Clone the repository.
git clone https://github.com/confidential-containers/guest-components.git
Inside the guest-components directory, you can build and run the tool with Cargo.
cargo run -p confidential-data-hub --bin secret
With the tool you can create a secret.
cargo run -p confidential-data-hub --bin secret seal vault --resource-uri kbs:///your/secret/here --provider kbs
A vault secret is fulfilled by retrieving a secret from a KBS inside the guest.
The locator of your secret is specified by resource-uri.
This command should return a base64 string which you will use in the next step.
Note
For vault secrets, the secret-cli tool does not upload your resource to the KBSs automatically. In addition to generating the secret string, you must also upload the resource to your KBS.Adding a sealed secret to Kubernetes
Create a secret from your secret string using kubectl.
kubectl create secret generic sealed-secret --from-literal='secret=sealed.fakejwsheader.ewogICAgInZlcnNpb24iOiAiMC4xLjAiLAogICAgInR5cGUiOiAidmF1bHQiLAogICAgIm5hbWUiOiAia2JzOi8vL2RlZmF1bHQvc2VhbGVkLXNlY3JldC90ZXN0IiwKICAgICJwcm92aWRlciI6ICJrYnMiLAogICAgInByb3ZpZGVyX3NldHRpbmdzIjoge30sCiAgICAiYW5ub3RhdGlvbnMiOiB7fQp9Cg==.fakesignature'
Note
Sealed secrets do not currently support integrity protection. This will be added in the future, but for now a fake signature and signature header are included within the secret.When using --from-literal you provide a mapping of secret keys and values.
The secret value should be the string generated in the previous step.
The secret key can be whatever you want, but make sure to use the same one in future steps.
This is separate from the name of the secret.
Deploying a sealed secret to a confidential workload
You can add your sealed secret to a workload yaml file.
You can expose your sealed secret as an environment variable.
apiVersion: v1
kind: Pod
metadata:
name: sealed-secret-pod
spec:
runtimeClassName: kata-qemu-coco-dev
containers:
- name: busybox
image: quay.io/prometheus/busybox:latest
imagePullPolicy: Always
command: ["echo", "$PROTECTED_SECRET"]
env:
- name: PROTECTED_SECRET
valueFrom:
secretKeyRef:
name: sealed-secret
key: secret
You can also expose your secret as a volume.
apiVersion: v1
kind: Pod
metadata:
name: secret-test-pod-cc
spec:
runtimeClassName: kata
containers:
- name: busybox
image: quay.io/prometheus/busybox:latest
imagePullPolicy: Always
command: ["cat", "/sealed/secret-value/secret"]
volumeMounts:
- name: sealed-secret-volume
mountPath: "/sealed/secret-value"
volumes:
- name: sealed-secret-volume
secret:
secretName: sealed-secret
Note
Currently sealed secret volumes must be mounted in the/sealed directory.
Advanced
Envelope Secrets
You can also create envelope secrets. With envelope secrets, the secret itself is included in the secret (unlike a vault secret, which is just a pointer to a secret). In an envelope secret, the secret value is wrapped and can be unwrapped by a KMS. This allows us to support models where the key for unwrapping secrets never leaves the KMS. It also decouples the secret from the KBS.
We currently support two KMSes for envelope secrets. See specific instructions for aliyun kms and eHSM.
4.6 - Signed Images
Procedures to generate and deploy signed OCI images with CoCo
TODO
5 - Attestation
Trusted Components for Attestation and Secret Management
Trustee contains tools and components for attesting confidential guests and providing secrets to them. Collectively, these components are known as Trustee. Trustee typically operates on behalf of the “workload provider” / “data owner” and interacts remotely with guest components.
Trustee is developed for the Confidential Containers project, but can be used with a wide variety of applications and hardware platforms.
Architecture
Trustee is flexible and can be deployed in several different configurations. This figure shows one common way to deploy these components in conjunction with certain guest components.
flowchart LR
AA -- attests guest ----> KBS
CDH -- requests resource --> KBS
subgraph Guest
CDH <.-> AA
end
subgraph Trustee
KBS -- validates evidence --> AS
RVPS -- provides reference values--> AS
end
client-tool -- configures --> KBS
Legend
CDH: Confidential Data HubAA: Attestation AgentKBS: Key Broker ServiceRVPS: Reference Value Provider ServiceAS: Attestation Service
5.1 - Key Broker Service (KBS)
This service facilitates remote attestation and secret delivery
The Confidential Containers Key Broker Service (KBS) facilitates remote attestation and secret delivery. The KBS is an implementation of a Relying Party from the Remote ATtestation ProcedureS (RATS) Architecture. The KBS itself does not validate attestation evidence. Instead, it relies on the Attestation-Service (AS) to verify TEE evidence.
In conjunction with the AS or Intel Trust Authority (ITA), the KBS supports the following TEEs:
- AMD SEV-SNP
- AMD SEV-SNP on Azure with vTPM
- Intel TDX
- Intel TDX on Azure with vTPM
- Intel SGX
- ARM CCA
- Hygon CSV
Deployment Configurations
The KBS can be deployed in several different environments, including as part of a docker compose cluster, part of a Kubernetes cluster or without any containerization. Additionally, the KBS can interact with other attestation components in different ways. This section focuses on the different ways the KBS can interact with other components.
Background Check Mode
Background check mode is a more straightforward and simple way to configure the Key Broker Service (KBS) and Attestation-Service (AS). The term “Background Check” is from the RATS architecture. In background check mode, the KBS directly forwards the hardware evidence of a confidential guest to the AS to validate. Once the validation passes, the KBS will release secrets to the confidential guest.
flowchart LR
AA -- attests guest --> KBS
CDH -- requests resource ----> KBS
subgraph Guest
AA <.-> CDH
end
subgraph Trustee
KBS -- validates evidence --> AS
end
In background check mode, the KBS is the relying party and the AS is the verifier.
Passport Mode
Passport mode decouples the provisioning of resources from the validation of evidence. In background check mode these tasks are already handled by separate components, but in passport mode they are decoupled even more. The term “Passport” is from the RATS architecture.
In passport mode, there are two Key Broker Services (KBSes), one that uses a KBS to verify the evidence and a second to provision resources.
flowchart LR
CDH -- requests resource ----> KBS2
AA -- attests guest --> KBS1
subgraph Guest
CDH <.-> AA
end
subgraph Trustee 1
KBS1 -- validates evidence --> AS
end
subgraph Trustee 2
KBS2
end
In the RATS passport model the client typically connects directly to the verifier to get an attestation token (a passport). In CoCo we do not support direct connections to the AS, so KBS1 serves as an intermediary. Together KBS1 and the AS represent the verifier. KBS2 is the relying party.
Passport mode is good for use cases when resource provisioning and attestation are handled by separate entities.
5.1.1 - KBS backed by AKV
This documentation describes how to mount secrets stored in Azure Key Vault into a KBS deployment
Premise
AKS
We assume an AKS cluster configured with Workload Identity and Key Vault Secrets Provider. The former provides a KBS pod with the privileges to access an Azure Key Vault (AKV) instance. The latter is an implementation of Kubernetes’ Secret Store CSI Driver, mapping secrets from external key vaults into pods. The guides below provide instructions on how to configure a cluster accordingly:
- Use the Azure Key Vault provider for Secrets Store CSI Driver in an Azure Kubernetes Service (AKS) cluster
- Use Microsoft Entra Workload ID with Azure Kubernetes Service (AKS)
AKV
There should be an AKV instance that has been configured with role based access control (RBAC), containing two secrets named coco_one coco_two for the purpose of the example. Find out how to configure your instance for RBAC in the guide below.
Provide access to Key Vault keys, certificates, and secrets with an Azure role-based access control
Note: You might have to toggle between Access Policy and RBAC modes to create your secrets on the CLI or via the Portal if your user doesn’t have the necessary role assignments.
CoCo
While the steps describe a deployment of KBS, the configuration of a Confidential Containers environment is out of scope for this document. CoCo should be configured with KBS as a Key Broker Client (KBC) and the resulting KBS deployment should be available and configured for confidential pods.
Azure environment
Configure your Resource group, Subscription and AKS cluster name. Adjust accordingly:
export SUBSCRIPTION_ID="$(az account show --query id -o tsv)"
export RESOURCE_GROUP=my-group
export KEYVAULT_NAME=kbs-secrets
export CLUSTER_NAME=coco
Instructions
Create Identity
Create a User managed identity for KBS:
az identity create --name kbs -g "$RESOURCE_GROUP"
export KBS_CLIENT_ID="$(az identity show -g "$RESOURCE_GROUP" --name kbs --query clientId -o tsv)"
export KBS_TENANT_ID=$(az aks show --name "$CLUSTER_NAME" --resource-group "$RESOURCE_GROUP" --query identity.tenantId -o tsv)
Assign a role to access secrets:
export KEYVAULT_SCOPE=$(az keyvault show --name "$KEYVAULT_NAME" --query id -o tsv)
az role assignment create --role "Key Vault Administrator" --assignee "$KBS_CLIENT_ID" --scope "$KEYVAULT_SCOPE"
Namespace
By default KBS is deployed into a coco-tenant Namespace:
export NAMESPACE=coco-tenant
kubectl create namespace $NAMESPACE
KBS identity and Service Account
Workload Identity provides individual pods with IAM privileges to access Azure infrastructure resources. An azure identity is bridged to a Service Account using OIDC and Federated Credentials. Those are scoped to a Namespace, we assume we deploy the Service Account and KBS into the default Namespace, adjust accordingly if necessary.
export AKS_OIDC_ISSUER="$(az aks show --resource-group "$RESOURCE_GROUP" --name "$CLUSTER_NAME" --query "oidcIssuerProfile.issuerUrl" -o tsv)"
az identity federated-credential create \
--name kbsfederatedidentity \
--identity-name kbs \
--resource-group "$RESOURCE_GROUP" \
--issuer "$AKS_OIDC_ISSUER" \
--subject "system:serviceaccount:${NAMESPACE}:kbs"
Create a Service Account object and annotate it with the identity’s client id.
cat <<EOF> service-account.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
azure.workload.identity/client-id: ${KBS_CLIENT_ID}
name: kbs
namespace: ${NAMESPACE}
EOF
kubectl apply -f service-account.yaml
Secret Provider Class
A Secret Provider Class specifies a set of secrets that should be made available to k8s workloads.
cat <<EOF> secret-provider-class.yaml
apiVersion: secrets-store.csi.x-k8s.io/v1
kind: SecretProviderClass
metadata:
name: ${KEYVAULT_NAME}
namespace: ${NAMESPACE}
spec:
provider: azure
parameters:
usePodIdentity: "false"
clientID: ${KBS_CLIENT_ID}
keyvaultName: ${KEYVAULT_NAME}
objects: |
array:
- |
objectName: coco_one
objectType: secret
- |
objectName: coco_two
objectType: secret
tenantId: ${KBS_TENANT_ID}
EOF
kubectl create -f secret-provider-class.yaml
Deploy KBS
The default KBS deployment needs to be extended with label annotations and CSI volume. The secrets are mounted into the storage hierarchy default/akv.
git clone https://github.com/confidential-containers/kbs.git
cd kbs
git checkout v0.8.2
cd kbs/config/kubernetes
mkdir akv
cat <<EOF> akv/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: coco-tenant
resources:
- ../base
patches:
- path: patch.yaml
target:
group: apps
kind: Deployment
name: kbs
version: v1
EOF
cat <<EOF> akv/patch.yaml
- op: add
path: /spec/template/metadata/labels/azure.workload.identity~1use
value: "true"
- op: add
path: /spec/template/spec/serviceAccountName
value: kbs
- op: add
path: /spec/template/spec/containers/0/volumeMounts/-
value:
name: secrets
mountPath: /opt/confidential-containers/kbs/repository/default/akv
readOnly: true
- op: add
path: /spec/template/spec/volumes/-
value:
name: secrets
csi:
driver: secrets-store.csi.k8s.io
readOnly: true
volumeAttributes:
secretProviderClass: ${KEYVAULT_NAME}
EOF
kubectl apply -k akv/
Test
The KBS pod should be running, the pod events should give indication of possible errors. From a confidential pod the AKV secrets should be retrievable via Confidential Data Hub:
$ kubectl exec -it deploy/nginx-coco -- curl http://127.0.0.1:8006/cdh/resource/default/akv/coco_one
a secret
5.2 - Attestation Service (AS)
This service verifies TEE evidence
The Attestation Service (AS or CoCo-AS) verifies hardware evidence. The AS was designed to be used with the Key Broker Service (KBS) for Confidential Containers, but it can be used in a wide variety of situations. The AS can be used anytime TEE evidence needs to be validated.
Today, the AS can validate evidence from the following TEEs:
- Intel TDX
- Intel SGX
- AMD SEV-SNP
- ARM CCA
- Hygon CSV
- Intel TDX with vTPM on Azure
- AMD SEV-SNP with vTPM on Azure
Overview
┌───────────────────────┐
┌───────────────────────┐ Evidence │ Attestation Service │
│ ├────────────►│ │
│ Verification Demander │ │ ┌────────┐ ┌──────────┴───────┐
│ (Such as KBS) │ │ │ Policy │ │ Reference Value │◄───Reference Value
│ │◄────────────┤ │ Engine │ │ Provider Service │
└───────────────────────┘ Attestation │ └────────┘ └──────────┬───────┘
Results Token │ │
│ ┌───────────────────┐ │
│ │ Verifier Drivers │ │
│ └───────────────────┘ │
│ │
└───────────────────────┘
The Attestation Service (AS) has a simple API. It receives attestation evidence and returns an attestation token containing the results of a two-step verification process. The AS can be consumed directly as a Rust crate (library) or built as a standalone service, exposing a REST or gRPC API. In Confidential Containers, the client of the AS is the Key Broker Service (KBS), but the evidence originates from the Attestation Agent inside the guest.
The AS has a two-step verification process.
- Verify the format and provenance of evidence itself (e.g. check the signature of the evidence).
- Appraise the claims presented in the evidence (e.g. check that measurements match reference values).
The first step is accomplished by one of the platform-specific Verifier Drivers. The second step is driven by the Policy Engine with help from the Reference Value Provider Service (RVPS).
5.3 - Reference Value Provider Service (RVPS)
This service manages reference values used to verify TEE evidence
Reference Value Provider Service (RVPS) is a component to receive software supply chain provenances / metadata, verify them and extract the reference values. All the reference values are stored inside RVPS. When Attestation Service (AS) queries specific software claims, RVPS will response with related reference values.
Architecture
RVPS contains the following components:
-
Pre-Processor: Pre-Processor contains a set of *wares (like middleware). These wares can process the input Message and then deliver it to the Extractors.
-
Extractors: Extractors has sub-modules to process different type of provenance. Each sub-module will consume the input Message, and then generate an output Reference Value.
-
Store: Store is a trait object, which can provide key-value like API. All verified reference values will be stored in the Store. When requested by Attestation Service (AS), related reference value will be provided.
Message Flow
The message flow of RVPS is like the following figure:

Message
A protocol helps to distribute provenance of binaries. It will be received and processed by RVPS, then RVPS will generate Reference Value if working correctly.
{
"version": <VERSION-NUMBER-STRING>,
"type": <TYPE-OF-THE-PROVENANCE-STRING>,
"provenance": #provenance,
}
"version": This field is the version of this message, making extensibility possible."type": This field specifies the concrete type of the provenance the message carries."provenance": This field is the main content passed to RVPS. This field contains the payload to be decrypted by RVPS. The meaning of the provenance depends on the type and concrete Extractor which process this.
Trust Digests
It is the reference values really requested and used by Attestation Service to compare with the gathered evidence generated from HW TEE. They are usually digests. To avoid ambiguity, they are named trust digests rather than reference values.
5.4 - KBS Client Tool
Simple tool to test or configure Key Broker Service and Attestation Service
This is a simple client for the Key Broker Client (KBS) that facilitates testing of the KBS and other basic attestation flows.
You can run this tool inside of a TEE to make a request with real attestation evidence. You can also provide pre-existing evidence or use the sample attester as a fallback.
The client tool can also be used to provision the KBS/AS with resources and policies.
6 - Examples
Example CoCo Deployments
6.1 - Azure
Cloud API Adaptor (CAA) on Azure
This documentation will walk you through setting up CAA (a.k.a. Peer Pods) on Azure Kubernetes Service (AKS). It explains how to deploy:
- A single worker node Kubernetes cluster using Azure Kubernetes Service (AKS)
- CAA on that Kubernetes cluster
- An Nginx pod backed by CAA pod VM
Pre-requisites
- Install Azure CLI by following instructions here.
- Install kubectl by following the instructions here.
- Ensure that the tools
curl,git,jqandsipcalcare installed.
Azure Preparation
Azure login
There are a bunch of steps that require you to be logged into your Azure account:
az login
Retrieve your subscription ID:
export AZURE_SUBSCRIPTION_ID=$(az account show --query id --output tsv)
Set the region:
export AZURE_REGION="eastus"
Note: We selected the
eastusregion as it not only offers AMD SEV-SNP machines but also has prebuilt pod VM images readily available.
export AZURE_REGION="eastus2"
Note: We selected the
eastus2region as it not only offers Intel TDX machines but also has prebuilt pod VM images readily available.
export AZURE_REGION="eastus"
Note: We have chose region
eastusbecause it has prebuilt pod VM images readily available.
Resource group
Note: Skip this step if you already have a resource group you want to use. Please, export the resource group name in the
AZURE_RESOURCE_GROUPenvironment variable.
Create an Azure resource group by running the following command:
export AZURE_RESOURCE_GROUP="caa-rg-$(date '+%Y%m%b%d%H%M%S')"
az group create \
--name "${AZURE_RESOURCE_GROUP}" \
--location "${AZURE_REGION}"
Deploy Kubernetes using AKS
Make changes to the following environment variable as you see fit:
export CLUSTER_NAME="caa-$(date '+%Y%m%b%d%H%M%S')"
export AKS_WORKER_USER_NAME="azuser"
export AKS_RG="${AZURE_RESOURCE_GROUP}-aks"
export SSH_KEY=~/.ssh/id_rsa.pub
Note: Optionally, deploy the worker nodes into an existing Azure Virtual Network (VNet) and subnet by adding the following flag:
--vnet-subnet-id $MY_SUBNET_ID.
Deploy AKS with single worker node to the same resource group you created earlier:
az aks create \
--resource-group "${AZURE_RESOURCE_GROUP}" \
--node-resource-group "${AKS_RG}" \
--name "${CLUSTER_NAME}" \
--enable-oidc-issuer \
--enable-workload-identity \
--location "${AZURE_REGION}" \
--node-count 1 \
--node-vm-size Standard_F4s_v2 \
--nodepool-labels node.kubernetes.io/worker= \
--ssh-key-value "${SSH_KEY}" \
--admin-username "${AKS_WORKER_USER_NAME}" \
--os-sku Ubuntu
Download kubeconfig locally to access the cluster using kubectl:
az aks get-credentials \
--resource-group "${AZURE_RESOURCE_GROUP}" \
--name "${CLUSTER_NAME}"
User assigned identity and federated credentials
CAA needs privileges to talk to Azure API. This privilege is granted to CAA by associating a workload identity to the CAA service account. This workload identity (a.k.a. user assigned identity) is given permissions to create VMs, fetch images and join networks in the next step.
Note: If you use an existing AKS cluster it might need to be configured to support workload identity and OpenID Connect (OIDC), please refer to the instructions in this guide.
Start by creating an identity for CAA:
export AZURE_WORKLOAD_IDENTITY_NAME="caa-${CLUSTER_NAME}"
az identity create \
--name "${AZURE_WORKLOAD_IDENTITY_NAME}" \
--resource-group "${AZURE_RESOURCE_GROUP}" \
--location "${AZURE_REGION}"
export USER_ASSIGNED_CLIENT_ID="$(az identity show \
--resource-group "${AZURE_RESOURCE_GROUP}" \
--name "${AZURE_WORKLOAD_IDENTITY_NAME}" \
--query 'clientId' \
-otsv)"
Networking
The VMs that will host Pods will commonly require access to internet services, e.g. to pull images from a public OCI registry. A discrete subnet can be created next to the AKS cluster subnet in the same VNet. We then attach a NAT gateway with a public IP to that subnet:
export AZURE_VNET_NAME="$(az network vnet list -g ${AKS_RG} --query '[].name' -o tsv)"
export AKS_CIDR="$(az network vnet show -n $AZURE_VNET_NAME -g $AKS_RG --query "subnets[?name == 'aks-subnet'].addressPrefix" -o tsv)"
# 10.224.0.0/16
export MASK="${AKS_CIDR#*/}"
# 16
PEERPOD_CIDR="$(sipcalc $AKS_CIDR -n 2 | grep ^Network | grep -v current | cut -d' ' -f2)/${MASK}"
# 10.225.0.0/16
az network public-ip create -g "$AKS_RG" -n peerpod
az network nat gateway create -g "$AKS_RG" -l "$AZURE_REGION" --public-ip-addresses peerpod -n peerpod
az network vnet subnet create -g "$AKS_RG" --vnet-name "$AZURE_VNET_NAME" --nat-gateway peerpod --address-prefixes "$PEERPOD_CIDR" -n peerpod
export AZURE_SUBNET_ID="$(az network vnet subnet show -g "$AKS_RG" --vnet-name "$AZURE_VNET_NAME" -n peerpod --query id -o tsv)"
AKS resource group permissions
For CAA to be able to manage VMs assign the identity VM and Network contributor roles, privileges to spawn VMs in $AZURE_RESOURCE_GROUP and attach to a VNet in $AKS_RG.
az role assignment create \
--role "Virtual Machine Contributor" \
--assignee "$USER_ASSIGNED_CLIENT_ID" \
--scope "/subscriptions/${AZURE_SUBSCRIPTION_ID}/resourcegroups/${AZURE_RESOURCE_GROUP}"
az role assignment create \
--role "Reader" \
--assignee "$USER_ASSIGNED_CLIENT_ID" \
--scope "/subscriptions/${AZURE_SUBSCRIPTION_ID}/resourcegroups/${AZURE_RESOURCE_GROUP}"
az role assignment create \
--role "Network Contributor" \
--assignee "$USER_ASSIGNED_CLIENT_ID" \
--scope "/subscriptions/${AZURE_SUBSCRIPTION_ID}/resourcegroups/${AKS_RG}"
Create the federated credential for the CAA ServiceAccount using the OIDC endpoint from the AKS cluster:
export AKS_OIDC_ISSUER="$(az aks show \
--name "${CLUSTER_NAME}" \
--resource-group "${AZURE_RESOURCE_GROUP}" \
--query "oidcIssuerProfile.issuerUrl" \
-otsv)"
az identity federated-credential create \
--name "caa-${CLUSTER_NAME}" \
--identity-name "${AZURE_WORKLOAD_IDENTITY_NAME}" \
--resource-group "${AZURE_RESOURCE_GROUP}" \
--issuer "${AKS_OIDC_ISSUER}" \
--subject system:serviceaccount:confidential-containers-system:cloud-api-adaptor \
--audience api://AzureADTokenExchange
Deploy CAA
Note: If you are using Calico Container Network Interface (CNI) on the Kubernetes cluster, then, configure Virtual Extensible LAN (VXLAN) encapsulation for all inter workload traffic.
Download the CAA deployment artifacts
export CAA_VERSION="0.10.0"
curl -LO "https://github.com/confidential-containers/cloud-api-adaptor/archive/refs/tags/v${CAA_VERSION}.tar.gz"
tar -xvzf "v${CAA_VERSION}.tar.gz"
cd "cloud-api-adaptor-${CAA_VERSION}/src/cloud-api-adaptor"
export CAA_BRANCH="main"
curl -LO "https://github.com/confidential-containers/cloud-api-adaptor/archive/refs/heads/${CAA_BRANCH}.tar.gz"
tar -xvzf "${CAA_BRANCH}.tar.gz"
cd "cloud-api-adaptor-${CAA_BRANCH}/src/cloud-api-adaptor"
This assumes that you already have the code ready to use. On your terminal change directory to the Cloud API Adaptor’s code base.
CAA pod VM image
Export this environment variable to use for the peer pod VM:
export AZURE_IMAGE_ID="/CommunityGalleries/cococommunity-42d8482d-92cd-415b-b332-7648bd978eff/Images/peerpod-podvm-ubuntu2204-cvm-snp/Versions/${CAA_VERSION}"
An automated job builds the pod VM image each night at 00:00 UTC. You can use that image by exporting the following environment variable:
SUCCESS_TIME=$(curl -s \
-H "Accept: application/vnd.github+json" \
"https://api.github.com/repos/confidential-containers/cloud-api-adaptor/actions/workflows/azure-podvm-image-nightly-build.yml/runs?status=success" \
| jq -r '.workflow_runs[0].updated_at')
export AZURE_IMAGE_ID="/CommunityGalleries/cocopodvm-d0e4f35f-5530-4b9c-8596-112487cdea85/Images/podvm_image0/Versions/$(date -u -jf "%Y-%m-%dT%H:%M:%SZ" "$SUCCESS_TIME" "+%Y.%m.%d" 2>/dev/null || date -d "$SUCCESS_TIME" +%Y.%m.%d)"
Above image version is in the format YYYY.MM.DD, so to use the latest image should be today’s date or yesterday’s date.
If you have made changes to the CAA code that affects the pod VM image and you want to deploy those changes then follow these instructions to build the pod VM image. Once image build is finished then export image id to the environment variable AZURE_IMAGE_ID.
CAA container image
Export the following environment variable to use the latest release image of CAA:
export CAA_IMAGE="quay.io/confidential-containers/cloud-api-adaptor"
export CAA_TAG="v0.10.0-amd64"
Export the following environment variable to use the image built by the CAA CI on each merge to main:
export CAA_IMAGE="quay.io/confidential-containers/cloud-api-adaptor"
Find an appropriate tag of pre-built image suitable to your needs here.
export CAA_TAG=""
Caution: You can also use the
latesttag but it is not recommended, because of its lack of version control and potential for unpredictable updates, impacting stability and reproducibility in deployments.
If you have made changes to the CAA code and you want to deploy those changes then follow these instructions to build the container image. Once the image is built export the environment variables CAA_IMAGE and CAA_TAG.
Annotate Service Account
Annotate the CAA Service Account with the workload identity’s CLIENT_ID and make the CAA DaemonSet use workload identity for authentication:
cat <<EOF > install/overlays/azure/workload-identity.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: cloud-api-adaptor-daemonset
namespace: confidential-containers-system
spec:
template:
metadata:
labels:
azure.workload.identity/use: "true"
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: cloud-api-adaptor
namespace: confidential-containers-system
annotations:
azure.workload.identity/client-id: "$USER_ASSIGNED_CLIENT_ID"
EOF
Select peer-pods machine type
export AZURE_INSTANCE_SIZE="Standard_DC2as_v5"
export DISABLECVM="false"
Find more AMD SEV-SNP machine types on this Azure documentation.
export AZURE_INSTANCE_SIZE="Standard_DC2es_v5"
export DISABLECVM="false"
Find more Intel TDX machine types on this Azure documentation.
export AZURE_INSTANCE_SIZE="Standard_D2as_v5"
export DISABLECVM="true"
Populate the kustomization.yaml file
Run the following command to update the kustomization.yaml file:
cat <<EOF > install/overlays/azure/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
bases:
- ../../yamls
images:
- name: cloud-api-adaptor
newName: "${CAA_IMAGE}"
newTag: "${CAA_TAG}"
generatorOptions:
disableNameSuffixHash: true
configMapGenerator:
- name: peer-pods-cm
namespace: confidential-containers-system
literals:
- CLOUD_PROVIDER="azure"
- AZURE_SUBSCRIPTION_ID="${AZURE_SUBSCRIPTION_ID}"
- AZURE_REGION="${AZURE_REGION}"
- AZURE_INSTANCE_SIZE="${AZURE_INSTANCE_SIZE}"
- AZURE_RESOURCE_GROUP="${AZURE_RESOURCE_GROUP}"
- AZURE_SUBNET_ID="${AZURE_SUBNET_ID}"
- AZURE_IMAGE_ID="${AZURE_IMAGE_ID}"
- DISABLECVM="${DISABLECVM}"
secretGenerator:
- name: peer-pods-secret
namespace: confidential-containers-system
- name: ssh-key-secret
namespace: confidential-containers-system
files:
- id_rsa.pub
patchesStrategicMerge:
- workload-identity.yaml
EOF
The SSH public key should be accessible to the kustomization.yaml file:
cp $SSH_KEY install/overlays/azure/id_rsa.pub
Deploy CAA on the Kubernetes cluster
Deploy coco operator:
export COCO_OPERATOR_VERSION="0.10.0"
kubectl apply -k "github.com/confidential-containers/operator/config/release?ref=v${COCO_OPERATOR_VERSION}"
kubectl apply -k "github.com/confidential-containers/operator/config/samples/ccruntime/peer-pods?ref=v${COCO_OPERATOR_VERSION}"
Run the following command to deploy CAA:
kubectl apply -k "install/overlays/azure"
Generic CAA deployment instructions are also described here.
Run sample application
Ensure runtimeclass is present
Verify that the runtimeclass is created after deploying CAA:
kubectl get runtimeclass
Once you can find a runtimeclass named kata-remote then you can be sure that the deployment was successful. A successful deployment will look like this:
$ kubectl get runtimeclass
NAME HANDLER AGE
kata-remote kata-remote 7m18s
Deploy workload
Create an nginx deployment:
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: default
spec:
selector:
matchLabels:
app: nginx
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
runtimeClassName: kata-remote
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
imagePullPolicy: Always
EOF
Ensure that the pod is up and running:
kubectl get pods -n default
You can verify that the peer pod VM was created by running the following command:
az vm list \
--resource-group "${AZURE_RESOURCE_GROUP}" \
--output table
Here you should see the VM associated with the pod nginx.
Note: If you run into problems then check the troubleshooting guide here.
Cleanup
If you wish to clean up the whole set up, you can delete the resource group by running the following command:
az group delete \
--name "${AZURE_RESOURCE_GROUP}" \
--yes --no-wait
7 - Use Cases
Common Applications of Confidential Containers
7.1 - Confidential AI
Confidential Containers for AI
Coming soon
7.2 - Secure Supply Chain
Securing build piplines with Confidential Containers
Coming soon
8 - Troubleshooting
Recovering from misconfigurations and bugs
Troubleshooting
Confidential Containers integrates several components. If you run into problems, it can sometimes be difficult to figure out what is going on or how to move forward. Here are some tips.
If you get stuck or find a bug, please make an issue on this repository or the repository for the component in question, e.g., the operator.
Kubernetes
To figure out which basic area you problem is in, first make sure that your Kubernetes
cluster can schedule non-confidential workloads on your worker node. Remove the kata-*
runtime class from your pod yaml and try to run a pod. If your pod still doesn’t run,
please refer to a more general Kubernetes troubleshooting guide.
If your cluster is healthy but you cannot start confidential containers, you might
be able get some helpful information from Kubernetes.
Try kubectl describe pod <your-pod>
Sometimes this will give you a useful message pointing to a failed attestation
or some sort of missing environment setup. Most of the time you will see a
generic message such as the following:
Failed to create pod sandbox: rpc error: code = Unknown desc = failed to create containerd task: failed to create shim: Failed to Check if grpc server is working: rpc error: code = DeadlineExceeded desc = timed out connecting to vsock 637456061:1024: unknown
Unfortunately, because this is a generic message, you’ll need to go deeper to figure out what is going on.
CoCo Debugging
A good next step is to figure out if things are breaking before or after the VM boots. You can see if there is a hypervisor process running with something like this.
ps -ef | grep qemu
If you are using a different hypervisor, adjust your command accordingly. If there are no hypervisor processes running on the worker node, the VM has either failed to start or was shutdown. If there is a hypervisor process, the problem is probably inside the guest.
Now is a good time to enable debug output for Kata and containerd.
To do this, first look at the containerd config file located at
/etc/containerd/config.toml. At the bottom of the file there should
be a section for each runtime class. For example:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.kata-qemu-sev]
cri_handler = "cc"
runtime_type = "io.containerd.kata-qemu-sev.v2"
privileged_without_host_devices = true
pod_annotations = ["io.katacontainers.*"]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.kata-qemu-sev.options]
ConfigPath = "/opt/confidential-containers/share/defaults/kata-containers/configuration-qemu-sev.toml"
The ConfigPath entry on the final line shows the path to the Kata configuration file that will be used
for that runtime class.
While you are looking at the containerd config, find the [debug] section near the top and set level
to debug. Make sure to restart containerd after editing the containerd config file.
You can do this with sudo systemctl restart containerd.
Now go to the Kata config file that matches your runtime class and enable every debug option available. You do not need to restart any daemons when changing the Kata config file; just run another pod or hope that Kubernetes restarts your existing pod. Note that enabling debug options in the Kata config file can change the attestation evidence of a confidential guest.
Now you should be able to view logs from containerd with the following:
sudo journalctl -xeu containerd
Kata writes many messages to this log. It’s good to know what you’re looking for. There are many generic messages that are insignificant, often arising from a VM not shutting down cleanly after an unrelated issue.
VM Doesn’t Start
If the VM has failed to start, you might have a problem with confidential computing support on your worker node. Make sure that you can start confidential VMs without confidential containers.
Check the containerd log for any obvious errors regarding VM boot.
Try searching the log for the string error or for the name
of your hypervisor i.e. qemu or qemu-system-x86_64.
If there are no obvious errors, try finding the hypervisor command line. This should be in the containerd log if you have enabled debug messages correctly.
It might be tempting to try running the hypervisor command directly from the command line, but this usually isn’t productive. Instead, try starting a standalone VM using the same kernel, initrd/disk, command line, firmware, and hypervisor that Kata uses. This might uncover some kind of system misconfiguration. You can also find these values in the Kata config file, but looking in the log is more direct.
Another way to print the hypervisor command is to create a bash script
that prints any arguments it is called with to a file. Then modify the
Kata config file so that the hypervisor path points to this script
rather than to the hypervisor. This method can also be used to add
additional parameters to the command line. Just have the bash script
call the hypervisor with whatever arguments it received plus any that
you want to add. This could be useful for enabling debugging or tracing
flags in your hypervisor. For instance, if you are using QEMU and SEV
you might want to add the argument --trace 'kvm_sev_*'. Make sure
that QEMU was built with an appropriate tracing backend.
VM Does Start
If the VM does start, search the containerd log for the string vmconsole.
This will show you any guest serial output. You might see some errors
coming from the kernel as the guest tries to boot. You might also see the
Kata agent starting. If the Kata agent has started, you can match
the output to the source to get some clues about what is happening.
You might also see something more obvious, like a panic coming from
the Kata agent.
Debug Console
One very useful debugging tool is the Kata guest debug console. You can enable this by editing the Kata agent configuration file and adding the lines
debug_console = true
debug_console_vport = 1026
Enabling the debug console via the Kata Configuration file will overwrite any settings in the agent configuration file in the guest initrd. Enabling the debug console will also change the launch measurement.
Once you’ve started a pod with the new configuration, get the id of the pod
you want to access. Do this via ps -ef | grep qemu or equivalent.
The id is the long id that shows up in many different arguments.
It should look like 1a9ab65be63b8b03dfd0c75036d27f0ed09eab38abb45337fea83acd3cd7bacd.
Once you have the id, you can use it to access the debug console.
sudo /opt/confidential-containers/bin/kata-runtime exec <id>
You might need to symlink the appropriate Kata configuration file for your runtime
class if the kata-runtime tries to look at the wrong one.
The debug console gives you access to the guest VM. This is a great way to investigate missing dependencies or incorrect configurations.
Guest Firmware Logs
If the VM is running but there is no guest output in the log,
the guest may have stalled in the firmware. Firmware output will
depend on your firmware and hypervisor. If you are using QEMU and OVMF,
you can see the OVMF output by adding -global isa-debugcon.iobase=0x402
and -debugcon file:/tmp/ovmf.log to the QEMU command line using the
redirect script described above.
Image Pulling
failed to create shim task: failed to mount “/run/kata-containers/shared/containers/CONTAINER_NAME/rootfs”
If your CoCo Pod gets an error like the one shown below, then it is likely the image pull policy is set to IfNotPresent, and the image has been found in the kubelet cache. It fails because the container runtime will not delegate to the Kata agent to pull the image inside the VM and the agent in turn will try to mount the bundle rootfs that only exist in the host filesystem.
Therefore, you must ensure that the image pull policy is set to Always for any CoCo pod. This way the images are always handled entirely by the agent inside the VM. It is worth mentioning we recognize that this behavior is sub-optimal, so the community provides solutions to avoid constant image downloads for each workload.
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 20s default-scheduler Successfully assigned default/coco-fedora-69d9f84cd7-j597j to virtlab1012
Normal Pulled 5s (x3 over 19s) kubelet Container image "docker.io/wainersm/coco-fedora_sshd@sha256:a7108f9f0080c429beb66e2cf0abff143c9eb9c7cf4dcde3241bc56c938d33b9" already present on machine
Normal Created 5s (x3 over 19s) kubelet Created container coco-fedora
Warning Failed 5s (x3 over 19s) kubelet Error: failed to create containerd task: failed to create shim task: failed to mount "/run/kata-containers/shared/containers/coco-fedora/rootfs" to "/run/kata-containers/coco-fedora/rootfs", with error: ENOENT: No such file or directory: unknown
Warning BackOff 4s (x3 over 18s) kubelet Back-off restarting failed container
9 - Contributing
Getting started with contributions
So you want to contribute to Confidential Containers? This guide will get you up to speed on the mechanics of the project and offer tips about how to work with the community and make great contributions.
First off, Confidential Containers (CoCo) is an open source project. You probably already knew that, but it’s good to be clear that we welcome contributions, involvement, and insight from everyone. Just make sure to follow the code of conduct.
CoCo is licensed with Apache License, Version 2.0.
This guide won’t cover the architecture of the project, but you’ll notice that there are many different repositories under the CoCo organization. A CoCo deployment integrates many different components. Fortunately the process for contributing to each of these subprojects is largely the same. There is one major exception. Most CoCo deployments leverage Kata Containers, which is an existing open source project. Kata has its own Contributor Guide that you should take a look at. You can contribute to CoCo by contributing to Kata, but this guide is focused on contributions made to repositories in the CoCo organization.
Connecting with the Community
You might already know exactly what you want to contribute and how. If not, if would be useful to interact with existing developers. There are several easy ways to do this.
Slack Channel
The best place to interact with the CoCo community is the
#confidential-containers channel in the CNCF Slack workspace.
This is a great place to ask any questions about the project
and to float ideas for future development.
Community Meeting
CoCo also has a weekly community meeting on Thursdays. See the agenda for more information. The community meeting usually has a packed agenda, but there is always time for a few basic questions.
GitHub Issue
You can also open issues in GitHub. Try to open your issue on the repository that is most closely related to your question. If you aren’t sure which repository is most relevant, you can open an issue on this repository. If you’re creating an issue that you plan to resolve, consider noting this in a comment so other developers know that someone is working on the problem.
Making Contributions
The mechanics of making a contribution are straightforward. We follow a typical GitHub contribution flow. All contributions should be made as GitHub pull requests. Make sure your PR includes a Developer Certificate of Origin (DCO) and follow any existing stylistic or organizational conventions. These requirements are explained in more detail below.
Some contributions are simpler than others. If you are new to the community it could be good to start with a few simple contributions to get used to the process. Larger contributions, especially ones that span multiple subprojects, or have implications on the trust model or project architecture, will usually require more discussion and review. Nonetheless, CoCo has a track record of responding to PRs quickly and merging PRs quickly.
If you are preparing a large contribution, it is wise to share your idea
with the community as early as possible. Consider making an RFC issue
that explains the changes. You might also try to break large contributions
into smaller steps.
Making a Pull Request
If you aren’t familiar with Git or the GitHub PR workflow, take a look at this section of the Kata Containers contributor guide. We have a few firm formatting requirements that you must follow, but in general if you are thoughtful about your work and responsive to review, you shouldn’t have any issues getting your PRs merged. The requirements that we do have are there to make everyone’s life a little easier. Don’t worry if you forget to follow one of them at first. You can always update your PR if necessary. If you have any ideas for how we can improve our processes, please suggest them to the community or make PR to this document.
Certificate of Origin
Every PR in every subproject is required to include a DCO. This is strictly enforced by the CI. Fortunately, it’s easy to comply with this requirement. At the end of the commit message for each of your commits add something like
Signed-off-by: Alex Ample <al@example.com>
You can add additional tags to credit other developers who worked on a commit or helped with it. See here for more information.
Coding Style
Please follow whatever stylistic and organizational conventions have been established in the subproject that you are contributing to.
Most CoCo subprojects use Rust. When using Rust, it is a good idea to run rustfmt and clippy
before submitting a PR.
Most subprojects will automatically run these tools via a workflow,
but you can also run the tools locally.
In most cases your code will not be accepted if it does not pass these tests.
Projects might have additional conventions that are not captured by these tools.
- Use
rustfmtto fix any mechanical style issues. Rustfmt uses a style which conforms to the Rust Style Guide. - Use
clippyto catch common mistakes and improve your Rust code.
You can install the above tools as follows.
$ rustup component add rustfmt clippy
Commit Format
Along with code your contribution will include commit messages.
As mentioned, commit messages are required to have a Signed-off-by footer.
Commit messages should not be empty.
Even if the commit is self-explanatory to you, include a short description of
what it does.
This helps reviewers and future developers.
The title of the commit should start with a subsystem. For example,
docs: update contributor guide
The “subsystem” describes the area of the code that the change applies to. It does not have to match a particular directory name in the source tree because it is a “hint” to the reader. The subsystem is generally a single word.
If the commit touches many different subsystems, you might want to split it into multiple commits. In general more smaller commits are preferred to fewer larger ones.
If a commit fixes an existing GitHub issue, include Fixes: #xxx in the commit message.
This will help GitHub link the commit to the issue, which shows other developers that
work is in progress.
Pull Request Format
The pull request itself must also have a name and a description. Like a commit, the pull request name should start with a subsystem. Unlike a commit, the pull request description does not become part of the Git log. The PR description can be more verbose. You might include a checklist of development steps or questions that you would like reviewers to consider. You can tag particular users or link a PR to an issue or another PR. If your PR depends on other PRs, you should specify this in the description. In general, the more context you provide in the description, the easier it will be for reviewers.
Reviews
In most subprojects your PR must be approved by two maintainers before it is merged. Reviews are also welcome from non-maintainers. For information about community structure, including how to become a maintainer, please see the governance document.
It may take a few iterations to address concerns raised by maintainers and other reviewers. Keep an eye on GitHub to see if you need to rebase your PR during this process. The web UI will report whether a PR can be automatically merged or if it conflicts with the base branch.
While CoCo reviewers tend to be responsive, many have a lot on their plate. If your PR is awaiting review, you can tag a reviewer to remind them to take a look. You can also ask for review in the CoCo Slack channel.
Continuous Integration
All subprojects have some form of CI and require some checks to pass before a PR can be merged. Some of the checks are:
- Static analysis checks.
- Unit tests.
- Functional tests.
- Integration tests.
If your PR does not pass a check, try to find the cause of the failure. If the cause is not related to your changes, you can ask a reviewer to re-run the tests or help troubleshoot.
With this guide, you’re well-prepared to contribute effectively to Confidential Containers. We appreciate your involvement in our open-source community!